
OSINT Tool: Pagodo


Reading Time: 4 Minutes
Google Dorking
Google Dorking is a technique used by hackers to find the information exposed accidentally to the internet. For example, log files with usernames and passwords or cameras, etc. It is done mostly by using the queries to go after a specific target gradually. Offensive Security maintains the Google Hacking Database (GHDB). It is a collection of Google searches, called dorks, that can be used to find potentially vulnerable boxes or other juicy info that is picked up by Google’s search bots.
Pagodo – Passive Google Dork
pagodo by opsdisk, automates Google searching for potentially vulnerable web pages and applications on the Internet. It replaces manually performing Google dork searches with a web GUI browser.
There are 2 parts. The first is ghdb_scraper.py that retrieves the latest Google dorks and the second portion is pagodo.py that leverages the information gathered by ghdb_scraper.py.
The core Google search library now uses the more flexible yagooglesearch instead of googlesearch. Check out the yagooglesearch README for a more in-depth explanation of the library differences and capabilities.
This version of pagodo also supports native HTTP(S) and SOCKS5 application support, so no more wrapping it in a tool like proxychains4 if you need proxy support. You can specify multiple proxies to use in a round-robin fashion by providing a comma separated string of proxies using the -p switch.
Installation
Scripts are written for Python 3.6+. Clone the git repository and install the requirements.
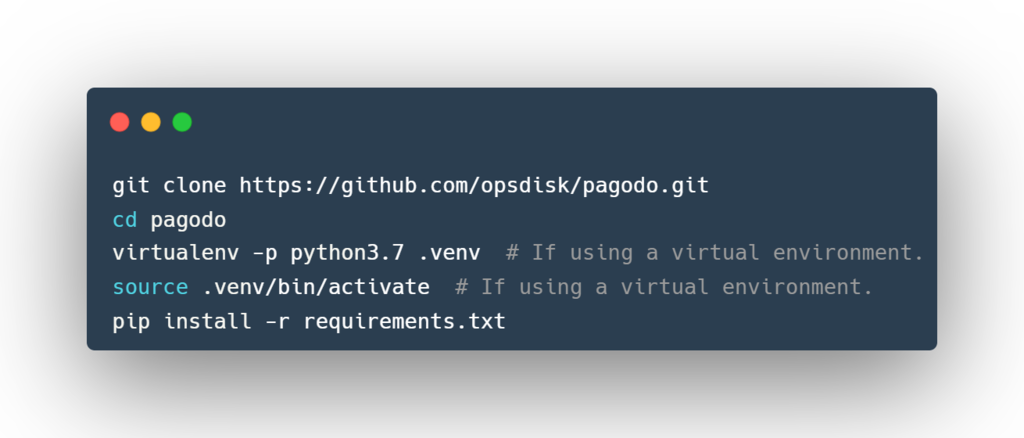
ghdb_scraper.py
To start off, pagodo.py needs a list of all the current Google dorks. The repo contains a dorks/ directory with the current dorks when the ghdb_scraper.py was last run. It’s advised to run ghdb_scraper.py to get the freshest data before running pagodo.py. The dorks/ directory contains:
- the all_google_dorks.txt file which contains all the Google dorks, one per line
- the all_google_dorks.json file which is the JSON response from GHDB
- Individual category dorks
Dork categories:

Using ghdb_scraper.py as a script
Write all dorks to all_google_dorks.txt, all_google_dorks.json, and individual categories if you want more contextual data about each dork.
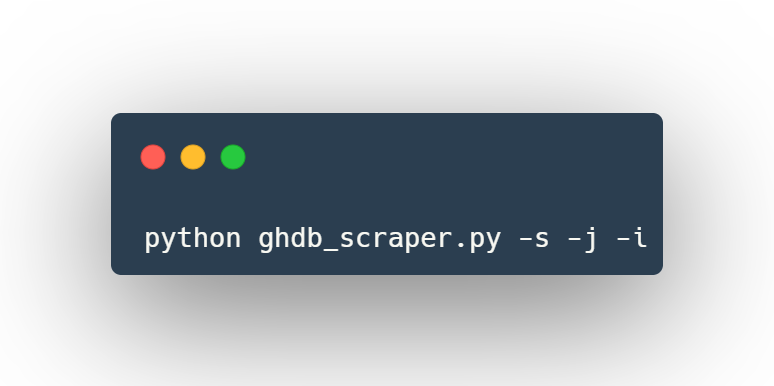
Using ghdb_scraper as a module
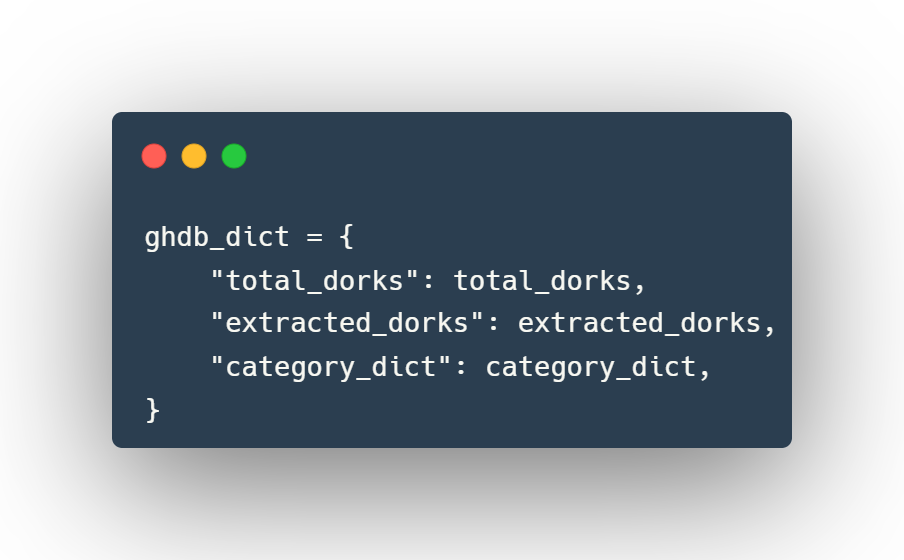
The ghdb_scraper.retrieve_google_dorks() function returns a dictionary with the following data structure:
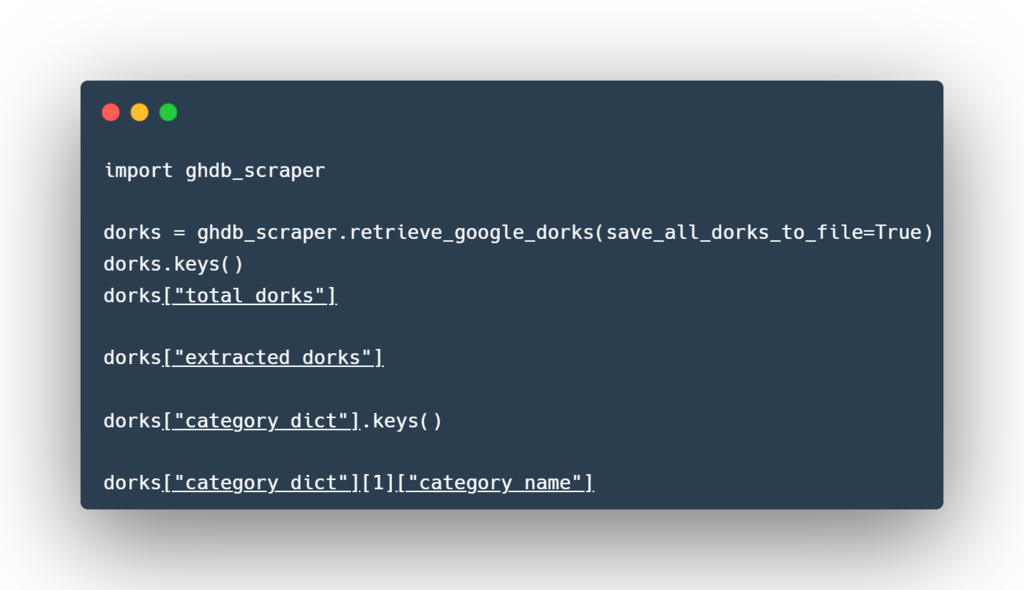
Using a Python shell (like python or ipython) to explore the data:
See Also: So you want to be a hacker?
Complete Offensive Security and Ethical Hacking Course
pagodo.py
Using pagodo.py as a script
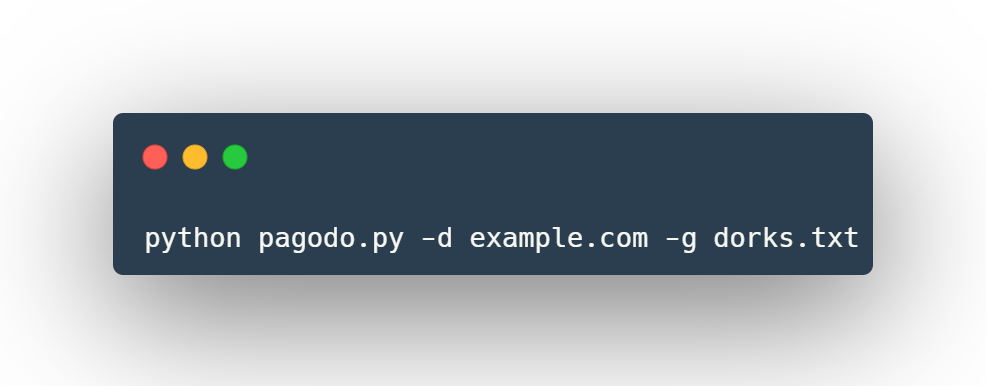
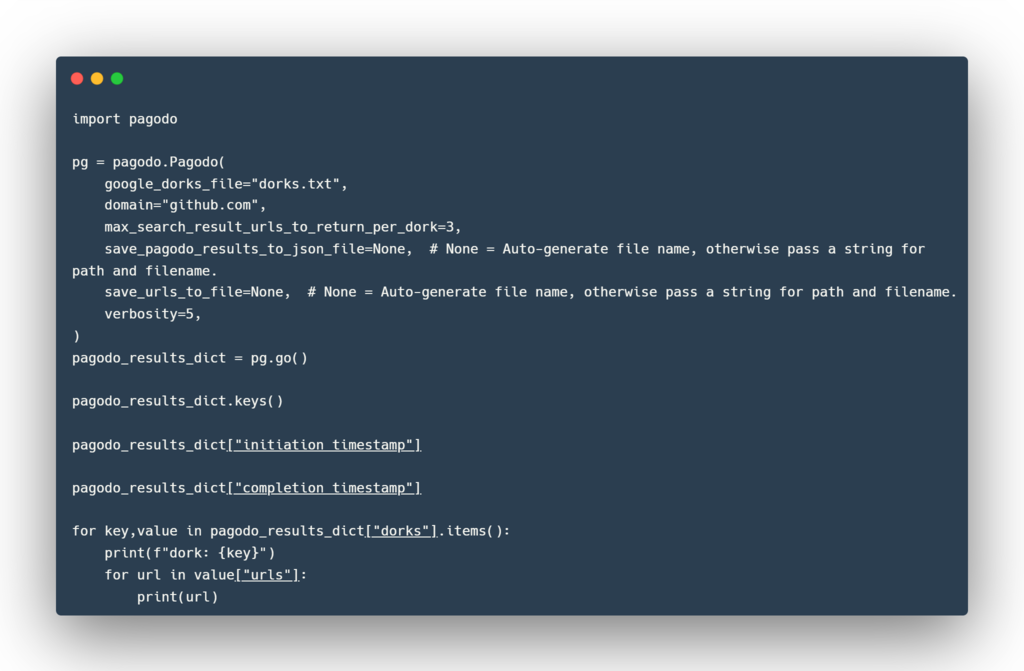
Using pagodo as a module
The pagodo.Pagodo.go() function returns a dictionary with the data structure below (dorks used are made up examples):

Using a Python shell (like python or ipython) to explore the data:
See Also: OSINT Tool: Metabigor
Tuning Results
Scope to a specific domain
The -d switch can be used to scope the results to a specific domain and functions as the Google search operator:

Wait time between Google dork searchers
- -i – Specify the minimum delay between dork searches, in seconds. Don’t make this too small, or your IP will get HTTP 429’d quickly.
- -x – Specify the maximum delay between dork searches, in seconds. Don’t make this too big or the searches will take a long time.
The values provided by -i and -x are used to generate a list of 20 randomly wait times, that are randomly selected between each different Google dork search.
Number of results to return
-m – The total max search results to return per Google dork. Each Google search request can pull back at most 100 results at a time, so if you pick -m 500, 5 separate search queries will have to be made for each Google dork search, which will increase the amount of time to complete.
Save Output
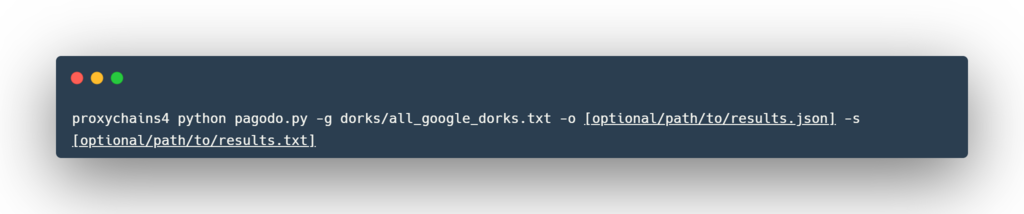
-o [optional/path/to/results.json] – Save output to a JSON file. If you do not specify a filename, a datetimestamped one will be generated.
-s [optional/path/to/results.txt] – Save URLs to a text file. If you do not specify a filename, a datetimestamped one will be generated.
Google is blocking me!
Performing 7300+ search requests to Google as fast as possible will simply not work. Google will rightfully detect it as a bot and block your IP for a set period of time. One solution is to use a bank of HTTP(S)/SOCKS proxies and pass them to pagodo
Native proxy support
Pass a comma separated string of proxies to pagodo using the -p switch.
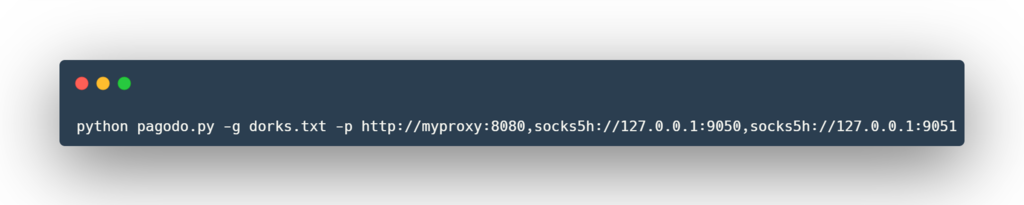
You could even decrease the -i and -x values because you will be leveraging different proxy IPs. The proxies passed to pagodo are selected by round robin.
proxychains4 support
Another solution is to use proxychains4 to round robin the lookups.
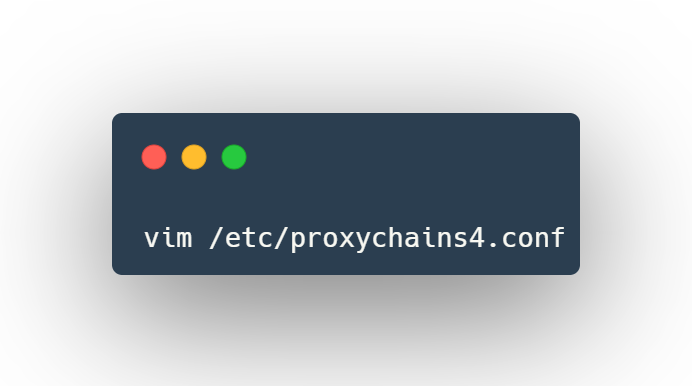
Install proxychains4
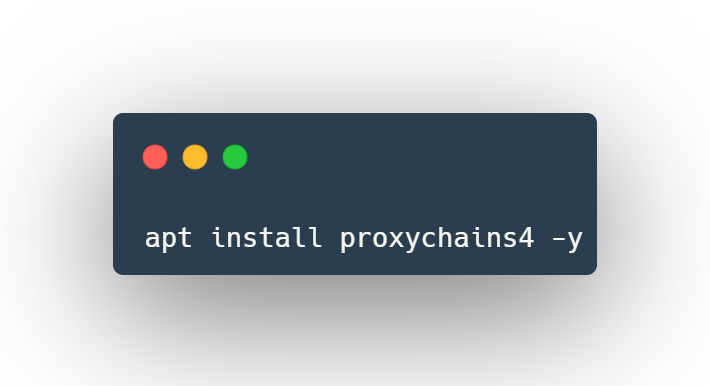
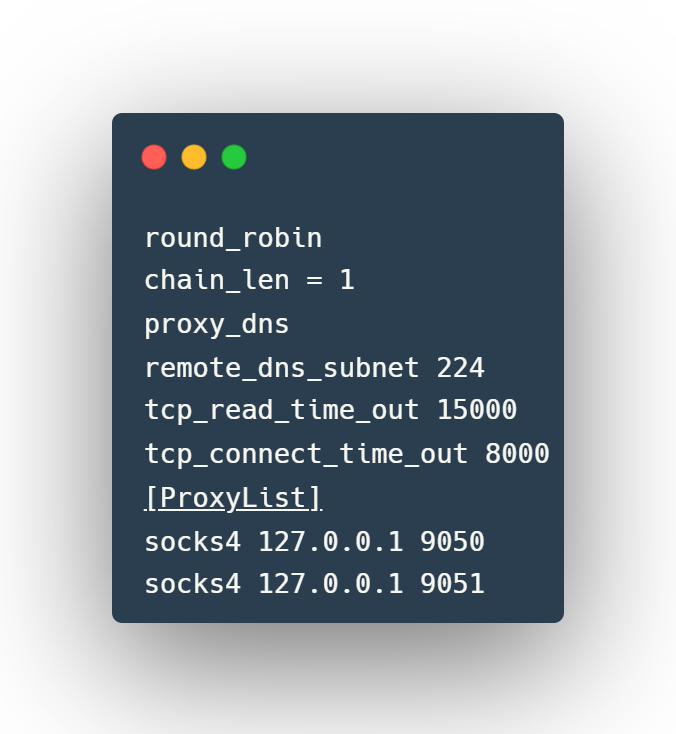
Edit the /etc/proxychains4.conf configuration file to round robin the look ups through different proxy servers. In the example below, 2 different dynamic socks proxies have been set up with different local listening ports (9050 and 9051).
Throw proxychains4 in front of the pagodo.py script and each request lookup will go through a different proxy (and thus source from a different IP).
Note that this may not appear natural to Google if you:
- Simulate “browsing” to google.com from IP #1
- Make the first search query from IP #2
- Simulate clicking “Next” to make the second search query from IP #3
- Simulate clicking “Next to make the third search query from IP #1
For that reason, using the built in -p proxy support is preferred because, as stated in the yagooglesearch documentation, the “provided proxy is used for the entire life cycle of the search to make it look more human, instead of rotating through various proxies for different portions of the search.”
Terms and Conditions
The terms and conditions for pagodo are the same terms and conditions found in yagooglesearch.
This code is supplied as-is and you are fully responsible for how it is used. Scraping Google Search results may violate their Terms of Service. Another Python Google search library had some interesting information/discussion on it:
- Original issue
- A response
- Author created a separate Terms and Conditions
- …that contained link to this blog
Google’s preferred method is to use their API.

Recent Tools

Offensive Security Tool: HExHTTP
HExHTTP is a tool designed to perform tests on HTTP …Recon Tool: getJS
getJS is a tool designed for extracting JavaScript sources from …Digital Forensics Tool: MemProcFS-Analyzer
MemProcFS-Analyzer is a PowerShell script designed to streamline memory forensics …Offensive Security Tool: Penelope
Penelope is a shell handler designed to be easy to …




Offensive Security & Ethical Hacking Course
Begin the learning curve of hacking now!

Information Security Solutions
Find out how Pentesting Services can help you.
