
Recon Tool: WayMore


Reading Time: 4 Minutes
Anyone who does Bug Bounty will have likely used the amazing waybackurls by TomNomNom. The idea behind waymore by xnlh4ck3r is to find even more links from the Wayback Machine than other existing tools.
The biggest difference between waymore and other tools is that it can also download the archived responses for URLs on wayback machine so that you can then search these for even more links, developer comments, extra parameters, and so on.
This tool gets URLs from:
- Wayback Machine (web.archive.org)
- Common Crawl (index.commoncrawl.org)
- Alien Vault OTX (otx.alienvault.com)
- URLScan (urlscan.io)
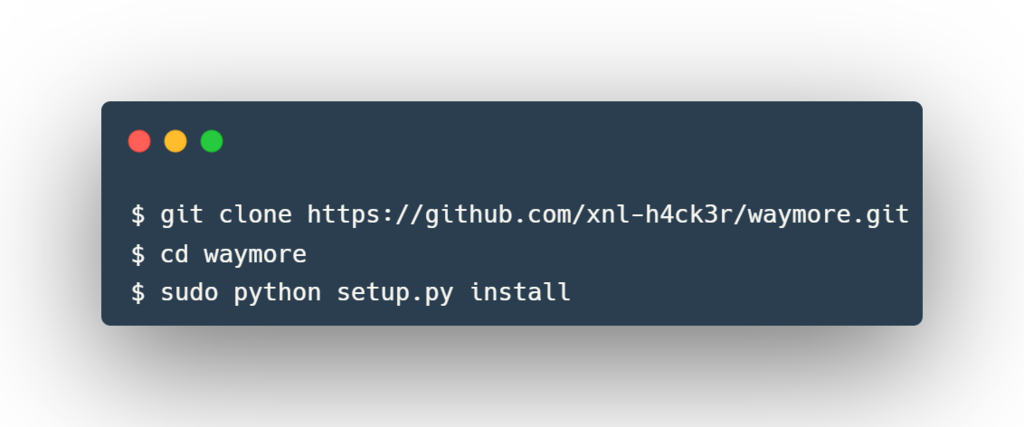
Installation
waymore supports Python 3.
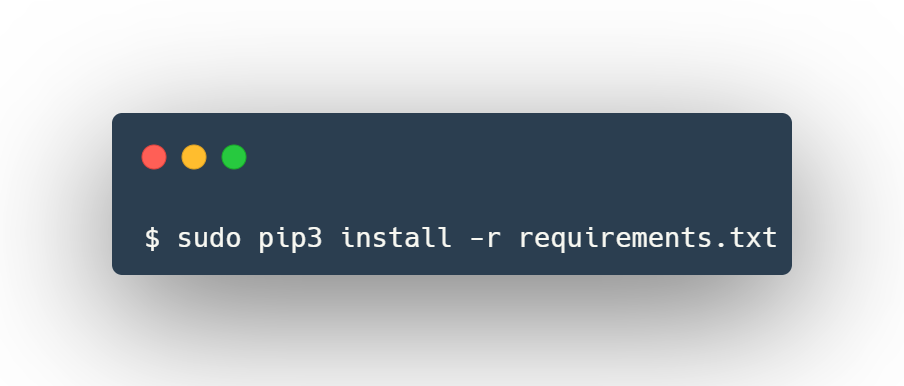
if you’re having a problem running the setup.py for whatever reason you can run the following to install the dependencies:
See Also: So you want to be a hacker?
Complete Offensive Security and Ethical Hacking Course
Usage
| Arg | Long Arg | Description |
| -i | –input | The target domain to find links for. This can be a domain only, or a domain with a specific path. If it is a domain only to get everything for that domain, don;t prefix with www. |
| -mode | The mode to run: U (retrieve URLs only), R (download Responses only) or B (Both). If -i is a domain only, then -mode will default to B. If -i is a domain with path then -mode will default to R. | |
| -n | –no-subs | Don’t include subdomains of the target domain (only used if input is not a domain with a specific path). |
| -f | –filter-responses-only | The initial links from Wayback Machine will not be filtered, only the responses that are downloaded, , e.g. it maybe useful to still see all available paths from the links even if you don’t want to check the content. |
| -l | –limit | How many responses will be saved (if -b is not passed). A positive value will get the first N results, a negative value will will get the last N results. A value of 0 will get ALL responses (default: 5000) |
| -from | –from-date | What date to get responses from. If not specified it will get from the earliest possible results. A partial value can be passed, e.g. 2016, 201805, etc. |
| -to | –to-date | What date to get responses to. If not specified it will get to the latest possible results. A partial value can be passed, e.g. 2021, 202112, etc. |
| -ci | –capture-interval | Filters the search on archive.org to only get at most 1 capture per hour (h), day (d) or month (m). This filter is used for responses only. The default is ‘d’ but can also be set to ‘none’ to not filter anything and get all responses. |
| -ra | –regex-after | RegEx for filtering purposes against links found from archive.org/commoncrawl.org AND responses downloaded. Only positive matches will be output. |
| -url-filename | Set the file name of downloaded responses to the URL that generated the response, otherwise it will be set to the hash value of the response. Using the hash value means multiple URLs that generated the same response will only result in one file being saved for that response. | |
| -xcc | Exclude checks to commoncrawl.org. Searching all their index collections can take a while, and often it may not return any extra URLs that weren’t already found on archive.org | |
| -xav | Exclude checks to alienvault.com. Searching all their pages can take a while, and often it may not return any extra URLs that weren’t already found on archive.org | |
| -lcc | Limit the number of Common Crawl index collections searched, e.g. -lcc 10 will just search the latest 10 collections.. As of June 2022 there are currently 88 collections. Setting to 0 (default) will search ALL collections. If you don’t want to search Common Crawl at all, use the -xcc option. | |
| -t | –timeout | This is for archived responses only! How many seconds to wait for the server to send data before giving up (default: 30) |
| -p | –processes | Basic multithreading is done when getting requests for a file of URLs. This argument determines the number of processes (threads) used (default: 3) |
| -r | –retries | The number of retries for requests that get connection error or rate limited (default: 1). |
| -v | –verbose | Verbose output |
| -h | –help | show the help message and exit |
Input and Mode
The input -i can either be a domain only, e.g. redbull.com or a specific domain and path, e.g. redbull.com/robots.txt.
There are different modes that can be run for waymore. The -mode argument can be 3 different value:
- U – URLs will be retrieved from archive.org, commoncrawl.org (if -xcc is not passed) and otx.alienvault.com (if -xvv is not passed)
- R – Responses will be downloaded from archive.org
- B – Both URLs and Responses will be retrieved
If the input was a specific URL, e.g. redbull.com/robots.txt then the -mode defaults to R. Only responses will be downloaded. You cannot change the mode to U or B for a domain with path because it isn’t necessary to retrieve URLs for a specific URL.
If the input is just a domain, e.g. redbull.com then the -mode defaults to B. It can be changed to U or R if required. When a domain only is passed then all URLs/responses are retrieved for that domain (and sub domains unless -n is passed). If the no sub domain option -n is passed then the www sub domain is still included by default.
See Also: OSINT Tool: Pagodo
config.yml
The config.yml file have filter values that can be updated to suit your needs. These are all provided as comma separated lists:
- FILTER_CODE – Exclusions used to exclude responses we will try to get from web.archive.org, and also for file names when -i is a directory, e.g. 301,302
- FILTER_MIME – MIME Content-Type exclusions used to filter links and responses from web.archive.org through their API, e.g. ‘text/css,image/jpeg
- FILTER_URL – Response code exclusions we will use to filter links and responses from web.archive.org through their API, e.g. .css,.jpg
NOTE: The MIME types cannot be filtered for Alien Vault results because they do not return that in the API response.
Output
In the path of the waymore.py file, a results directory will be created. Within that, a directory will be created with target domain (or domain with path) passed with -i. When run, the following files are created in the target directory:
- waymore.txt – If -mode is U or B, this file will contain links from archive.org. Also any additional links from commoncrawl.org (if -xcc wasn’t passed) and otx.alienvault.com (if -xav wasn’t passed).
- index.txt – If -mode is R or B, and -url-filname was not passed then archived responses will be downloaded and hash values will be used for the saved file names. This file contains a comma separated list of <hash>,<archive URL>,<timestamp> in case you need to know which URLs produced which response.
- *.xnl – These archived response files will be created if -mode was R or B. If -url-filename was passed the the file names will be the archive URL that generated the response, e.g. https–example.com-robots.txt.xnl, otherwise the file name will be a hash value, e.g. 7960113391501.xnl. Using hash values mean that less files will be written as there will only be one file per unique response. These archived responses are edited, before being saved, to remove any reference to web.archive.org.
Info and Suggestions
The number of links found, and then potentially the number of files archived responses you will download could potentially be HUGE for many domains. This tool isn’t about speed, it’s about finding more, so be patient.
There is a -p option to increase the number of processes (used when retrieving links from all sources, and downloading archived responses from archive.org). However, although it may not be as fast as you’d like, one suggestion would be by leaving -p at the default of 3 because you can find issues with getting responses with higher values. We don’t want to cause these services any problems, so be sensible!
You can use the -f option if you want the waymore.txt to contain ALL possible links. It could be useful to see all possible paths and maybe parameters. Any filters will always be applied to downloading archived responses though. You don’t want to waste time downloading thousands of images!
Using the -v option can help see what is happening behind the scenes and could help you if you aren’t getting the output you are expecting.
All the MIME Content Types of URL’s found (by all sources except Alien Vault) will be displayed when -v is used. This may help to add further exclusions if you find you still get back things you don’t want to see. If you spot a MIME type that is being included but you don’t want that going forward, add it to the FILTER_MIME in config.yml. It should be noted that sometimes the MIME type on archive.org is stored as unk and unknown instead of the real MIME so the filter won’t necessarily remove it from their results. The FILTER_URL config settings can be used to remove these afterwards. For example, if a GIF has MIME type unk instead of image/gif (and that’s in FILTER_MIME) then it won’t get filtered, but if the url is https://target.com/assets/logo.gif and .gif is in FILTER_URL it won’t get requested.
If config.yml doesn’t exist, or the entries for filters, aren’t in the file, then default filters are used. It’s better to have the file and review these to ensure you are getting what you need.
There can potentially be millions of responses so make sure you set filters, but also the Limit (-l), From Date (-from), To Date (-to) and/or Capture Interval (-ci) if you need to. The limit defaults to 5000, but say you wanted to get the latest 20,000 responses from 2015 up until January 2018… you would pass -l -20000 -from 2015 -to 201801. The Capture Interval determines how many responses will get downloaded for a particular URL within a specified period, e.g. if you set to m you will only get one response per month for a URL. The default d will likely greatly reduce the number of responses and unlikely to miss many unique responses unless a target changed something more than once in a given day.
The provider API servers aren’t designed to cope with huge volumes, so be sensible and considerate about what you hit them with!
Some Basic Examples
Example 1
Just get the URLs from all sources for redbull.com (-mode U is just for URLs, so no responses are downloaded):
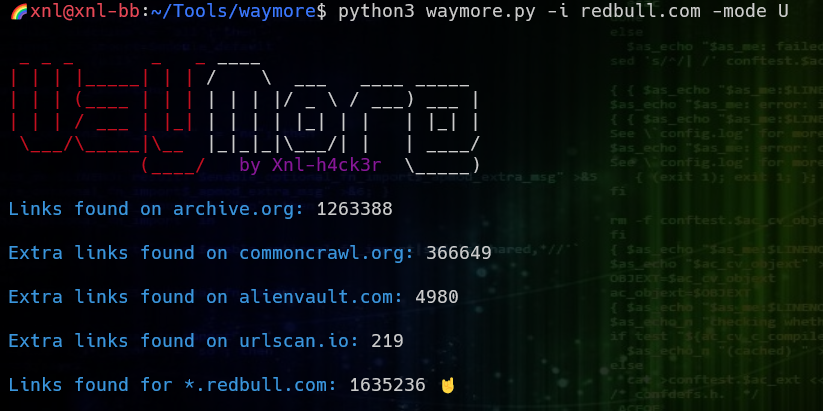
The URLs are saved in the same path as waymore.py under results/redbull.com/waymore.txt
Example 2
Get ALL the URLs from Wayback for redbull.com (no filters are applied with -f, and no URLs are retrieved from Commone Crawl because -xcc is passed, or from Alien Vault because -xav is passed). Save the FIRST 1000 responses that are found starting from 2015 (-l 1000 -from 2015):
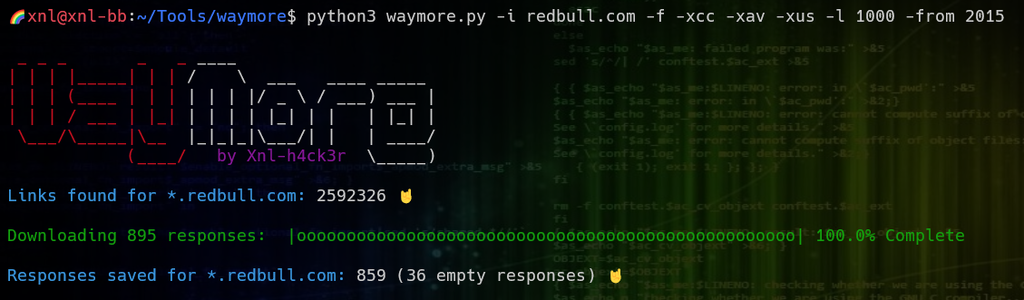
The -mode wasn’t explicitly set so defaults to B (Both – retrieve URLs AND download responses). A file will be created for each unique response and also saved in results/redbull.com/:
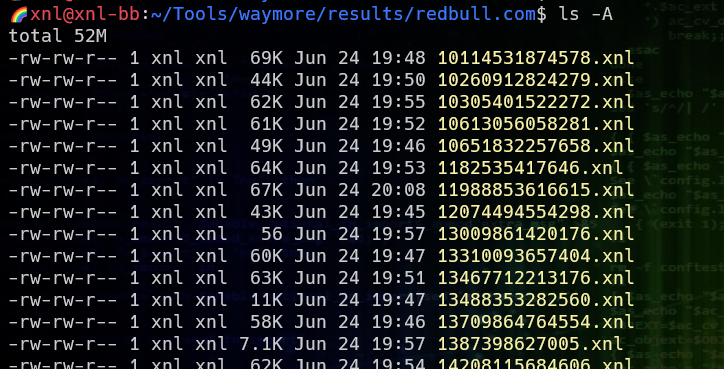
There will also be a file results/redbull.com/index.txt that will contain a reference to what URLs gave the response for what file, e.g.
4847147712618,https://web.archive.org/web/20220426044405/https://www.redbull.com/additional-services/geo ,2022-06-24 20:07:50.603486
where 4847147712618 is the hash value of the response in 4847147712618.xnl, the 2nd value is the Wayback Machine URL where you can view the actual page that was archived, and the 3rd is a time stamp of when the response was downloaded.
Finding Way More URLs!
So now you have lots of archived responses and you want to find extra links? Easy! Why not use xnLinkFinder? For example:
python3 xnLinkFinder -i ~/Tools/waymore/results/redbull.com -sp https://www.redbull.com -sf redbull.com -o redbull.txt
Or run other tools such as trufflehog or gf over the directory of responses to find even more from the archived responses!
TODO
- Allow a file of domains (or domains with paths) to be passed with -i argument
- Add an -oss argument that accepts a file of Out Of Scope subdomains/URLs that will not be returned in the output, or have any responses downloaded
- Add an -o output option to specify a directory in which you want the search domain’s directory created (to store responses), or just for a specific file if set -mode U to get just a file of URL’s

Recent Tools

Offensive Security Tool: DS Viper
DS Viper is a post-exploitation tool specifically designed to bypass …Offensive Security Tool: Bxss – Blind XSS Scanner
Blind XSS Scanner is a tool that can be used …Vulnerability Management Tool: CVE Prioritizer
CVE Prioritizer is a vulnerability management tool designed to help …Offensive Security Tool: HExHTTP
HExHTTP is a tool designed to perform tests on HTTP …




Offensive Security & Ethical Hacking Course
Begin the learning curve of hacking now!

Information Security Solutions
Find out how Pentesting Services can help you.
